Text Mining
Published on Aug 15, 2016
Abstract
The volume of information circulating in a typical enterprise continues to increase. Knowledge hidden in the information however, is not fully utilized, as most of the information is described in textual form (as sentences).
A large amount of text information can be analyzed objectively and efficiently with Text Mining.The field of text mining has received a lot of attention due to the ever increasing need for managing the information that resides in the vast amount of available text documents. Text documents are characterized by their unstructured nature. Ever increasing sources of such unstructured information include the World Wide Web, biological databases, news articles, emails etc.
Text mining is defined as the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources. A key element is the linking together of the extracted information together to form new facts or new hypotheses to be explored further by more conventional means of experimentation. As the amount of unstructured data increases, text-mining tools will be increasingly valuable. A future trend is integration of data mining and text mining into a single system, a combination known as duo-mining
Introduction of Text Mining
Text Mining is the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources. A key element is the linking together of the extracted information together to form new facts or new hypotheses to be explored further by more conventional means of experimentation. Text mining is different from what are familiar with in web search. In search, the user is typically looking for something that is already known and has been written by someone else. The problem is pushing aside all the material that currently is not relevant to your needs in order to find the relevant information. In text mining, the goal is to discover unknown information, something that no one yet knows and so could not have yet written down.
Machine intelligence is a problem for text mining. Natural language has developed to help humans communicate with one another and record information. Computers are a long way from comprehending natural language. Humans have the ability to distinguish and apply linguistic patterns to text and humans can easily overcome obstacles that computers cannot easily handle such as slang, spelling variations and contextual meaning. However, although our language capabilities allow us to comprehend unstructured data, we lack the computer’s ability to process text in large volumes or at high speeds. Figure depicts a generic process model for a text mining application.
Starting with a collection of documents, a text mining tool would retrieve a particular document and preprocess it by checking format and character sets. Then it would go through a text analysis phase, sometimes repeating techniques until information is extracted. Three text analysis techniques are shown in the example, but many other combinations of techniques could be used depending on the goals of the organization. The resulting information can be placed in a management information system, yielding an abundant amount of knowledge for the user of that system.
Topic Tracking :
A topic tracking system works by keeping user profiles and, based on the documents the user views, predicts other documents of interest to the user. Yahoo offers a free topic tracking tool (www.alerts.yahoo.com) that allows users to choose keywords and notifies them when news relating to those topics becomes available. Topic tracking technology does have limitations, however. For example, if a user sets up an alert for “text mining”, s/he will receive several news stories on mining for minerals, and very few that are actually on text mining.
Some of the better text mining tools let users select particular categories of interest or the software automatically can even infer the user’s interests based on his/her reading history and click-through information. There are many areas where topic tracking can be applied in industry. It can be used to alert companies anytime a competitor is in the news.
This allows them to keep up with competitive products or changes in the market. Similarly, businesses might want to track news on their own company and products.
It could also be used in the medical industry by doctors and other people looking for new treatments for illnesses and who wish to keep up on the latest advancements. Individuals in the field of education could also use topic tracking to be sure they have the latest references for research in their area of interest.
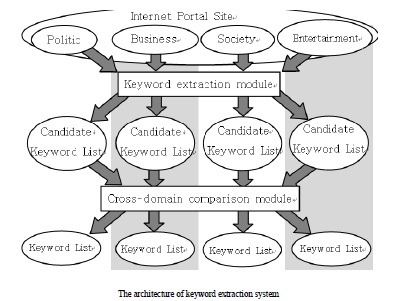
Keywords are a set of significant words in an article that gives high-level description of its contents to readers. Identifying keywords from a large amount of on-line news data is very useful in that it can produce a short summary of news articles. As on-line text documents rapidly increase in size with the growth of WWW, keyword extraction has become a basis of several text mining applications such as search engine, text categorization, summarization, and topic detection.
Manual keyword extraction is an extremely difficult and time consuming task; in fact, it is almost impossible to extract keywords manually in case of news articles published in a single day due to their volume. For a rapid use of keywords, we need to establish an automated process that extracts keywords from news articles. The architecture of keyword extraction system is presented in figure . HTML news pages are gathered from a Internet portal site. And candidate keywords are extracted throw keyword extraction module. And finally keywords are extracted by cross-domain comparison module. Keyword extraction module is described in detail.
