Apache Cassandra
Published on Nov 14, 2015
Abstract
Cassandra is open source and is in development at Apache. The Apache Cassandra project brings together Dynamo’s fully distributed design and Bigtables Column family based data model.
Cassandra is adapting to recent advances in distributed algorithms like Accural style failure detection and others. Cassandra is proven as it is in use by Digg, Facebook, Twitter, Reddit, Rackspace, Cloudkick, Cisco. The largest production cluster has over 100 TB of data in over 150 machines. It is Fault tolerant, decentralizes and gives the control to developers to choose between synchronous and asynchronous data replication. It offers rich data model, to efficiently compute using key and value pairs. It is highly scalable both in terms of storage volume and request throughput while not being subject to any single point of failure. It is durable and supports third party applications. Cassandra aims to run on top of an infrastructure of hundreds of nodes (possibly spread across different data centers).
At this scale, small and large components fail continuously. The way Cassandra manages the persistent state in the face of these failures drives the reliability and scalability of the software systems relying on this service. While in many ways Cassandra resembles a database and shares many design and implementation strategies therewith, Cassandra does not support a full relational data model; instead, it provides clients with a simple data model that supports dynamic control over data layout and format. Cassandra system was designed to run on cheap commodity hardware and handle high write throughput while not sacrificing read efficiency.
What is Cassandra?
Apache Cassandra is a highly scalable and high-performance distributed database management system that can serve as both an operational datastore (the “system of record”) for online/transactional applications, and as a read-intensive database for business intelligence systems. Cassandra is able to manage the distribution of data across multiple data centers and offers incremental scalability with no single points of failure. It is a NoSQL database that is decentralized (No single point of failure), elastic (Linear Scalability), fault Tolerant(Replication), optimized for writes, reads. It is a structured storage system over a P2P network. Cassandra uses a synthesis of well-known techniques to achieve scalability and availability. Cassandra is a distributed storage system for managing structured data that is designed to scale to a very large size across many commodity servers, with no single point of failure.
The idea is to run on top of an infrastructure of hundreds of nodes, where small and large components in the data centers fail continuously. Over the edge, Cassandra achieves scalability, high performance, high availability and applicability. It does not support a full relational data model. Instead it provides clients with a simple data model as explained later.
Many modern businesses have outgrown the typical RDBMS use case and are in need of data management software that offers more. Sharding was a stop-gap measure, but architectural limitations, and the management complexity it requires, make it unacceptable for many mainstream organizations. Successful web companies like Facebook, Yahoo, Google, and others like them, first exposed the need for a more forward-thinking method beyond sharding that managed all types of data, but it wasn’t long before that need became prevalent in nearly every industry.
“Apache Cassandra is an open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, column-oriented database that bases its distribution design on Amazon’s Dynamo and its data model on Google’s Bigtable. Created at Facebook, it is now used at some of the most popular sites on the Web.” Here we see a lot of complicated words such as distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, column-oriented etc. so let’s examine them in brief.
Comparing the Cassandra Data Model to a Relational Database
The Cassandra data model is designed for distributed data on a very large scale. Although it is natural to want to compare the Cassandra data model to a relational database, they are really quite different. In a relational database, data is stored in tables and the tables comprising an application are typically related to each other. Data is usually normalized to reduce redundant entries, and tables are joined on common keys to satisfy a given query. For example, consider a simple application that allows users to create blog entries. In this application, blog entries are categorized by subject area (sports, fashion, etc.).

In Cassandra, the keyspace is the container for your application data, similar to a database or schema in a relational database. Inside the keyspace are one or more column family objects, which are analogous to tables. Column families contain columns, and a set of related columns is identified by an application-supplied row key. Each row in a column family is not required to have the same set of columns. Cassandra does not enforce relationships between column families the way that relational databases do between tables: there are no formal foreign keys in cassandra, and joining column families at query time is not supported. Each column family has a self-contained set of columns that are intended to be accessed together to satisfy specific queries from your application.
For example, using the blog application example, you might have a column family for user data and blog entries similar to the relational model. Other column families (or secondary indexes) could then be added to support the queries your application needs to perform. For example, to answer the queries "what users subscribe to my blog" or "show me all of the blog entries about fashion" or "show me the most recent entries for the blogs I subscribe to", you would need to design additional column families (or add secondary indexes) to support those queries. Keep in mind that some denormalization of data is usually required.
Cassandra Architecture
Cassandra can satisfy many data-driven application use cases through a carefully thought-out architecture designed to manage all forms of modern data, scale to meet the requirements of “big data” management, offer linear performance scale-out capabilities, and deliver the type of high availability that most every online, 24x7 application needs. At its foundation, Cassandra is a peer-to-peer distributed data management system where every node is essentially the same with respect to how it functions in the cluster. In Cassandra, there is no concept of a “master node” or anything similar, with the benefit being derived that no single point of failure exists for any key process or function.
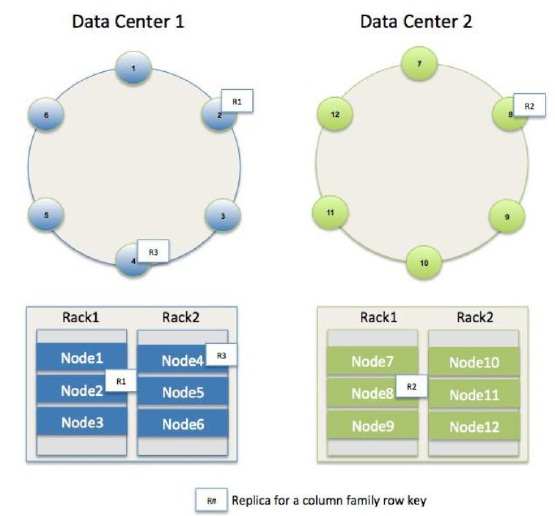
The scale-out aspect of Cassandra allows node additions to occur with no disruption to application uptime. Capacity to handle increasing I/O traffic or incoming data volumes is added easily and requires no special ETL processes or other data movement work to be performed manually. Instead, Cassandra automatically partitions data across nodes once one or more nodes have been added to a cluster and “seeds” the new nodes from existing machines in the cluster. Data redundancy to protect against hardware failure and other data loss scenarios is also built into and managed transparently by Cassandra. Further, this capability can be configured to be quite sophisticated so data can be distributed across multiple, geographically dispersed data centers, between different physical racks in a data center, and between public cloud providers and on-premise managed data centers.