Case Based Reasoning System
Published on Nov 14, 2015
Abstract
Case-based reasoning is a recent approach to problem solving and learning that has got a lot of attention over the last few years. Originating in the US, the basic idea and underlying theories have spread to other continents, and we are now within a period of highly active research in case-based reasoning.
Case-based reasoning means using old experiences to understand and solve new problems. In case-based reasoning, a reasoner remembers a previous situation similar to the current one and uses that to solve the new problem. In this a descriptive framework of CBR system is explained along with steps needed to build a CBR system. Guidelines for using CBR system and advantages of using it are also discussed in this topic. According to Riesbeck & Schank “A case based reasoner solves new problems by adapting solution that were used to solve old problems “.
Case-based reasoning means using old experiences to understand and solve new problems. In case-based reasoning, a reasoner remembers a previous situation similar to the current one and uses that to solve the new problem. According to Aamodt & Plazza case based reasoning system is used to solve a problem by remembering a previous similar situation and by reusing information and knowledge of that situation .Case based reasoning can mean adapting old solutions to meet new demands; using old cases to explain new situations; using old cases to critique new solutions; or reasoning from precedents to interpret a new situation or create an equitable solution to a new problem. The field of case-based reasoning (CBR), which has a relatively young history, arose out of the research in cognitive science. The earliest contributions in this area were from Roger Schank and his colleagues at Yale University.
The first system that might be called a case-based reasoner was the CYRUS system, developed by Janet Kolodner, at Yale University. CYRUS was based on Schank's dynamic memory model of problem solving and learning. Case-based reasoning (CBR) puts forward a paradigmatic way to attack AI issues, namely problem solving, learning, usage of general and specific knowledge, combining different reasoning methods, etc. In particular CBR emphasizes problem solving and learning as two sides of the same coin: problem solving uses the results of past learning episodes while problem solving provides the backbone of the experience from which learning advances.
The CBR cycle
At the highest level of generality, a general CBR cycle may be described by the following four Processes:
1. RETRIEVE the most similar case or cases
2. REUSE the information and knowledge in that case to solve the problem
3. REVISE the proposed solution
4. RETAIN the parts of this experience likely to be useful for future problem solving
A new problem is solved by retrieving one or more previously experienced cases, reusing the case in one way or another, revising the solution based on reusing a previous case, and retaining the new experience by incorporating it into the existing knowledge-base (case-base). The four processes each involve a number of more specific steps, which will be described in the task model. This cycle is illustrated below
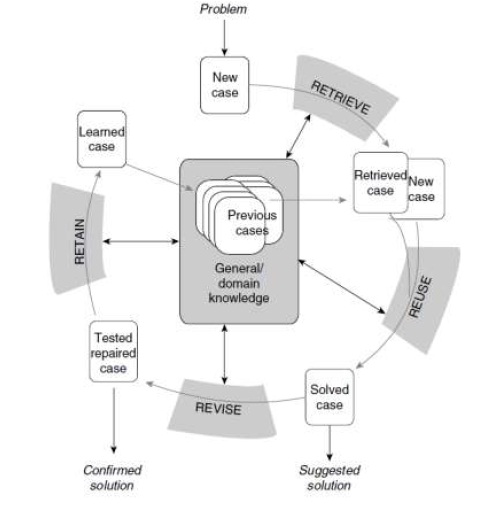
An initial description of a problem defines a new case. This new case is used to RETRIEVE a case from the collection of previous cases. The retrieved case is combined with the new case - through REUSE - into a solved case, i.e. a proposed solution to the initial problem. Through the REVISE process this solution is tested for success, e.g. by being applied to the real world environment or evaluated by a teacher, and repaired if failed. During RETAIN, useful experience is retained for future reuse, and the case base is updated by a new learned case, or by modification of some existing cases. As indicated in the figure, general knowledge usually plays a part in this cycle, by supporting the CBR processes. This support may range from very weak (or none) to very strong, depending on the type of CBR method. By general knowledge we here mean general domain-dependent knowledge, as opposed to specific knowledge embodied by cases.
Case Revision
When a case solution generated by the reuse phase is not correct, an opportunity for learning from failure arises. This phase is called case revision and consists of two tasks: (1) evaluate the case solution generated by reuse. If successful, learning from the success (2) otherwise repair the case solution using domain-specific knowledge.
1. Evaluate solution
The evaluation task takes the result from applying the solution in the real environment (asking a teacher or performing the task in the real world). This is usually a step outside the CBR system, involves the application of a suggested solution to the real problem. The results from applying the solution may take some time to appear, depending on the type of application. In a medical decision support system, the success or failure of a treatment may take from a few hours up to several months. The case may still be learned, and be available in the case base in the intermediate period, but it has to be marked as a nonevaluated case. A solution may also be applied to a simulation program that is able to generate a correct solution.
2. Repair fault
Case repair involves detecting the errors of the current solution and retrieving or generating explanations for them. A second task of the revision phase is the solution repair task. This task uses the failure explanations to modify the solution in such a way that failures do not occur. The repair module possesses general causal knowledge and domain knowledge about how to disable or compensate causes of errors in the domain. The revised plan can then be retained directly or it can be evaluated and repaired again.
Case Retainment - Learning
This is the process of incorporating what is useful to retain from the new problem solving episode into the existing knowledge. The learning from success or failure of the proposed solution is triggered by the outcome of the evaluation and possible repair. It involves selecting which information from the case to retain, in what form to retain it, how to index the case for later retrieval from similar problems, and how to integrate the new case in the memory structure.
1. Extract
In CBR the case base is updated no matter how the problem was solved. If it was solved by use of a previous case, a new case may be built or the old case may be generalized to subsume the present case as well. If the problem was solved by other methods, including asking the user, an entirely new case will have to be constructed. In any case, a decision needs to be made about what to use as the source of learning. Relevant problem descriptors and problem solutions are obvious candidates. But an explanation or another form of justification of why a solution is a solution to the problem may also be marked for inclusion in a new case.
The last type of structure that may be extracted for learning is the problem solving method, i.e. the strategic reasoning path, making the system suitable for derivational reuse. Failures, i.e. information from the Revise task, may also be extracted and retained, either as separate failure cases or within total-problem cases. When a failure is encountered, the system can then get a reminding to a previous similar failure, and use the failure case to improve its understanding of - and correct - the present failure.
2. Index
The 'indexing problem' is a central and much focused problem in casebased reasoning. It amounts to deciding what type of indexes to use for future retrieval, and how to structure the search space of indexes. Direct indexes, as previously mentioned, skips the latter step, but there is still the problem of identifying what type of indexes to use. This is actually a knowledge acquisition problem, and should be analyzed as part of the domain knowledge analysis and modeling step. A trivial solution to the problem is of course to use all input features as indices.
3. Integrate
This is the final step of updating the knowledge base with new case knowledge. If no new case and index set has been constructed, it is the main step of Retain. By modifying the indexing of existing cases, CBR systems learn to become better similarity assessors. The tuning of existing indexes is an important part of CBR learning. Index strengths or importance for a particular case or solution are adjusted due to the success or failure of using the case to solve the input problem. For features that have been judged relevant for retrieving a successful case, the association with the case is strengthened, while it is weakened for features that lead to unsuccessful cases being retrieved.
Case Indexing
Case indexing refers to assigning indices to cases for future retrieval and comparisons. This choice of indices is important to being able to retrieve the right case at the right time. This is because the indices of a case will determine in which context it will be retrieved in future. These are some suggestions for choosing indices Indices must be both predictive and predictive in a useful manner. This means that they should reflect the important aspects of the case, the attributes that influenced the outcome of the case and also those which will describe the circumstances in which it is expected that they should be retrieved in the future.
Indices should be abstract enough to allow for that cases retrieval in all the circumstances in which the case will be useful, but not too abstract. When a case’s indices are too abstract that case may be retrieved in too many situations, or too much processing would be required to match cases. Although assigning indexes is still largely a manual process relies on human experts, various attempts of using automated methods were proposed in the literature.
Case Retrieval
Case retrieval is the process of finding within the case base those cases that are the closest to the current case. To carry out case retrieval there must be criteria that determine how a case is judged to be appropriate for retrieval and a mechanism to control how the case base is searched. The selection criteria is necessary to decide which case is the best one to retrieve, that is, to determine how close the current and stored cases are. The actual processes involved in retrieving a case from the case base depend very much on the memory model and indexing procedures used. Retrieval methods employed by researchers and implementers are extremely diverse, ranging from a simple nearest neighbor search to the use of intelligent agents. We discuss here the most common, traditional methods.
Conclusion
Case-based reasoning (CBR) puts forward a paradigmatic way to attack AI issues, namely problem solving, learning, usage of general and specific knowledge, combining different reasoning methods, etc. In particular we have seen that CBR emphasizes problem solving and learning as two sides of the same coin: problem solving uses the results of past learning episodes while problem solving provides the backbone of the experience from which learning advances. The trends of CBR applications clearly indicates that we will initially see a lot of help desk applications around.
This type of systems may open up for a more general coupling of CBR – and AI in general - to information systems. The use of cases for human browsing and decision making is also likely to lead to an increased interest in intelligent computer-aided learning, training, and teaching. The strong role of user interaction, of flexible user control, and the drive towards total interactiveness of systems favours a case-based approach to intelligent computer assistance, since CBR systems are able to continually learn from, and evolve through, the capturing and retainment of past experiences. Case-based reasoning has blown a fresh wind and a well justified degree of optimism into AI in general and knowledge based decision support systems in particular. The growing amount of ongoing CBR research - within an AI community that has learned from its previous experiences - has the potential of leading to significant breakthroughs of AI methods and applications.
References
[1]. Aamodt A. and Plaza E.(1994) ,Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches. AI Communications. IOS Press, Vol. 7: 1, pp. 39-59
[2]. David B. Leake (1996) , Case Based Reasoning : Experiences ,Lessons and Future Directions AAAI Press/MIT Press
[3]. Sankar K. Pal and Simon C. K. Shiu (2004),Foundations Of Soft Case-based Reasoning, A john wiley & sons, inc., Publication